

Which Of The Following Changes Would Not Be Accounted For Using The Prospective Approach?
Introduction
Linear Regression is still the nearly prominently used statistical technique in information science industry and in academia to explicate relationships between features.
A total of 1,355 people registered for this skill test. It was specially designed for you to test your knowledge on linear regression techniques. If you are i of those who missed out on this skill exam, here are the questions and solutions. Yous missed on the real fourth dimension test, only tin read this article to observe out how many could have answered correctly.
Here is the leaderboard for the participants who took the test.
Overall Distribution
Below is the distribution of the scores of the participants:
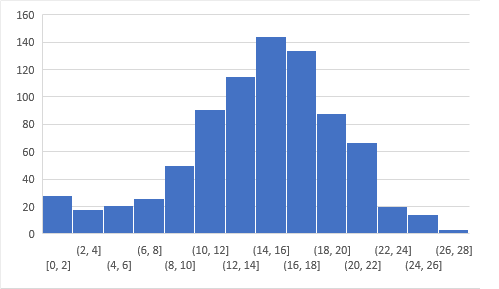
Yous can access the scores here. More than 800 people participated in the skill examination and the highest score obtained was 28.
Helpful Resources
Here are some resource to become in depth knowledge in the subject.
-
5 Questions which tin teach y'all Multiple Regression (with R and Python)
-
Going Deeper into Regression Analysis with Assumptions, Plots & Solutions
-
seven Types of Regression Techniques you should know!
Are you a beginner in Machine Learning? Do you lot want to main the concepts of Linear Regression and Machine Learning? Here is a beginner-friendly grade to assist you in your journey –
- Certified AI & ML Blackbelt+ Program
- Practical Automobile Learning Course
Skill exam Questions and Answers
1) True-False: Linear Regression is a supervised machine learning algorithm.
A) TRUE
B) False
Solution: (A)
Yes, Linear regression is a supervised learning algorithm because it uses true labels for training. Supervised learning algorithm should have input variable (ten) and an output variable (Y) for each example.
ii) True-False: Linear Regression is mainly used for Regression.
A) TRUE
B) Fake
Solution: (A)
Linear Regression has dependent variables that have continuous values.
iii) Truthful-False: Information technology is possible to design a Linear regression algorithm using a neural network?
A) Truthful
B) FALSE
Solution: (A)
Truthful. A Neural network tin can exist used every bit a universal approximator, and so it can definitely implement a linear regression algorithm.
4) Which of the following methods practice we utilize to find the best fit line for information in Linear Regression?
A) Least Foursquare Error
B) Maximum Likelihood
C) Logarithmic Loss
D) Both A and B
Solution: (A)
In linear regression, we attempt to minimize the least square errors of the model to identify the line of best fit.
5) Which of the following evaluation metrics tin can be used to evaluate a model while modeling a continuous output variable?
A) AUC-ROC
B) Accuracy
C) Logloss
D) Mean-Squared-Mistake
Solution: (D)
Since linear regression gives output as continuous values, so in such case we utilize mean squared error metric to evaluate the model operation. Remaining options are use in case of a classification problem.
vi) True-Simulated: Lasso Regularization can be used for variable choice in Linear Regression.
A) True
B) FALSE
Solution: (A)
True, In instance of lasso regression we apply absolute penalty which makes some of the coefficients nix.
7) Which of the following is truthful about Residuals ?
A) Lower is amend
B) College is better
C) A or B depend on the situation
D) None of these
Solution: (A)
Residuals refer to the mistake values of the model. Therefore lower residuals are desired.
8) Suppose that we accept N independent variables (X1,X2… Xn) and dependent variable is Y. Now Imagine that you are applying linear regression past plumbing fixtures the best fit line using least square mistake on this information.
Yous constitute that correlation coefficient for one of information technology's variable(Say X1) with Y is -0.95.
Which of the following is true for X1?
A) Relation betwixt the X1 and Y is weak
B) Relation between the X1 and Y is strong
C) Relation between the X1 and Y is neutral
D) Correlation can't estimate the human relationship
Solution: (B)
The accented value of the correlation coefficient denotes the strength of the relationship. Since absolute correlation is very loftier it ways that the human relationship is strong between X1 and Y.
nine) Looking at to a higher place two characteristics, which of the following pick is the right for Pearson correlation between V1 and V2?
If you are given the two variables V1 and V2 and they are following below two characteristics.
1. If V1 increases so V2 also increases
2. If V1 decreases then V2 beliefs is unknown
A) Pearson correlation will be shut to 1
B) Pearson correlation will be close to -1
C) Pearson correlation volition exist close to 0
D) None of these
Solution: (D)
Nosotros cannot comment on the correlation coefficient by using just argument 1. Nosotros demand to consider the both of these two statements. Consider V1 as ten and V2 equally |ten|. The correlation coefficient would non be shut to 1 in such a case.
x) Suppose Pearson correlation between V1 and V2 is zero. In such case, is information technology right to conclude that V1 and V2 do not have whatever relation between them?
A) TRUE
B) FALSE
Solution: (B)
Pearson correlation coefficient between 2 variables might exist naught fifty-fifty when they have a relationship betwixt them. If the correlation coefficient is zero, it just means that that they don't motion together. We tin take examples like y=|x| or y=x^2.
xi) Which of the post-obit offsets, do nosotros apply in linear regression's least foursquare line fit? Suppose horizontal axis is contained variable and vertical axis is dependent variable.
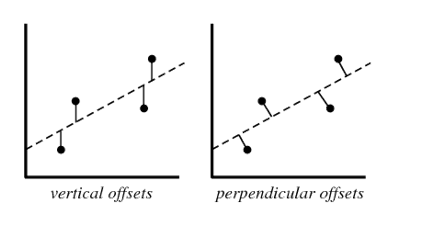
A) Vertical offset
B) Perpendicular offset
C) Both, depending on the situation
D) None of above
Solution: (A)
We ever consider residuals as vertical offsets. We calculate the direct differences between bodily value and the Y labels. Perpendicular offset are useful in case of PCA.
12) True- False: Overfitting is more than probable when you have huge corporeality of data to train?
A) Truthful
B) False
Solution: (B)
With a modest training dataset, information technology's easier to find a hypothesis to fit the training information exactly i.east. overfitting.
thirteen) We can also compute the coefficient of linear regression with the assist of an analytical method chosen "Normal Equation". Which of the following is/are true about Normal Equation?
- We don't accept to choose the learning rate
- It becomes slow when number of features is very large
- Thers is no need to iterate
A) 1 and 2
B) ane and three
C) ii and 3
D) 1,two and 3
Solution: (D)
Instead of slope descent, Normal Equation can too exist used to find coefficients. Refer this article for read more about normal equation.
14) Which of the following statement is truthful nigh sum of residuals of A and B?
Below graphs testify two fitted regression lines (A & B) on randomly generated data. At present, I want to find the sum of residuals in both cases A and B.
Note:
- Scale is aforementioned in both graphs for both axis.
- X axis is independent variable and Y-axis is dependent variable.

A) A has higher sum of residuals than B
B) A has lower sum of residual than B
C) Both have same sum of residuals
D) None of these
Solution: (C)
Sum of residuals volition always be zero, therefore both take aforementioned sum of residuals
Question Context 15-17:
Suppose you accept fitted a complex regression model on a dataset. Now, you are using Ridge regression with penality x.
15) Choose the option which describes bias in best manner.
A) In case of very large x; bias is low
B) In case of very big ten; bias is high
C) We can't say nigh bias
D) None of these
Solution: (B)
If the penalisation is very large it means model is less complex, therefore the bias would be high.
16) What volition happen when you utilize very big penalisation?
A) Some of the coefficient will become accented zippo
B) Some of the coefficient will approach zero but non absolute zero
C) Both A and B depending on the situation
D) None of these
Solution: (B)
In lasso some of the coefficient value get zero, but in case of Ridge, the coefficients become close to zero but not aught.
17) What will happen when you apply very large penalisation in case of Lasso?
A) Some of the coefficient volition become nix
B) Some of the coefficient will be approaching to zero but not absolute cypher
C) Both A and B depending on the situation
D) None of these
Solution: (A)
As already discussed, lasso applies accented penalty, so some of the coefficients will get null.
eighteen) Which of the following statement is true about outliers in Linear regression?
A) Linear regression is sensitive to outliers
B) Linear regression is not sensitive to outliers
C) Tin can't say
D) None of these
Solution: (A)
The slope of the regression line will change due to outliers in virtually of the cases. And so Linear Regression is sensitive to outliers.
xix) Suppose you plotted a besprinkle plot between the residuals and predicted values in linear regression and you lot establish that there is a relationship between them. Which of the following conclusion practice you make about this situation?
A) Since the there is a relationship means our model is non skillful
B) Since the there is a relationship means our model is good
C) Tin can't say
D) None of these
Solution: (A)
At that place should not be any relationship between predicted values and residuals. If there exists any relationship between them,it means that the model has not perfectly captured the information in the data.
Question Context 20-22:
Suppose that y'all accept a dataset D1 and you design a linear regression model of caste 3 polynomial and you lot found that the training and testing fault is "0" or in some other terms information technology perfectly fits the data.
20) What will happen when you lot fit degree iv polynomial in linear regression?
A) In that location are high chances that degree four polynomial will over fit the data
B) There are high chances that degree iv polynomial will under fit the data
C) Can't say
D) None of these
Solution: (A)
Since is more degree 4 will be more than circuitous(overfit the data) than the caste 3 model so it will again perfectly fit the data. In such case training fault will exist zero but test error may not be nada.
21) What volition happen when you lot fit degree 2 polynomial in linear regression?
A) It is high chances that caste 2 polynomial will over fit the data
B) Information technology is high chances that degree 2 polynomial will under fit the data
C) Tin't say
D) None of these
Solution: (B)
If a caste 3 polynomial fits the data perfectly, it's highly likely that a simpler model(degree two polynomial) might under fit the data.
22) In terms of bias and variance. Which of the following is true when yous fit degree 2 polynomial?
A) Bias will be high, variance will be high
B) Bias will be depression, variance will exist high
C) Bias volition exist loftier, variance will exist depression
D) Bias volition be depression, variance will be low
Solution: (C)
Since a degree 2 polynomial volition be less complex equally compared to degree three, the bias volition be high and variance will exist low.
Question Context 23:
Which of the post-obit is truthful nigh below graphs(A,B, C left to right) between the cost function and Number of iterations?
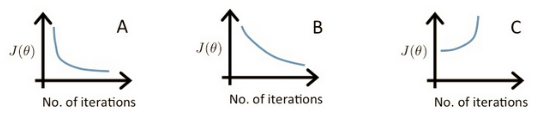
23) Suppose l1, l2 and l3 are the iii learning rates for A,B,C respectively. Which of the post-obit is true about l1,l2 and l3?
A) l2 < l1 < l3
B) l1 > l2 > l3
C) l1 = l2 = l3
D) None of these
Solution: (A)
In case of high learning rate, step will be high, the objective function will decrease quickly initially, simply it will not observe the global minima and objective role starts increasing later a few iterations.
In case of depression learning charge per unit, the footstep will be small. So the objective part will subtract slowly
Question Context 24-25:
We take been given a dataset with north records in which nosotros accept input attribute as x and output aspect as y. Suppose we use a linear regression method to model this information. To test our linear regressor, we split the data in training set and test set randomly.
24) Now we increase the training set size gradually. As the training gear up size increases, what practice you expect will happen with the mean preparation mistake?
A) Increase
B) Decrease
C) Remain abiding
D) Tin't Say
Solution: (D)
Preparation error may increment or decrease depending on the values that are used to fit the model. If the values used to train contain more outliers gradually, so the error might just increase.
25) What do you lot look will happen with bias and variance as yous increase the size of training information?
A) Bias increases and Variance increases
B) Bias decreases and Variance increases
C) Bias decreases and Variance decreases
D) Bias increases and Variance decreases
E) Can't Say Imitation
Solution: (D)
As nosotros increase the size of the training data, the bias would increase while the variance would decrease.
Question Context 26:
Consider the post-obit information where ane input(X) and 1 output(Y) is given.
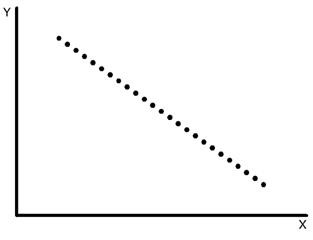
26) What would be the root hateful foursquare training error for this data if you run a Linear Regression model of the class (Y = A0+A1X)?
A) Less than 0
B) Greater than goose egg
C) Equal to 0
D) None of these
Solution: (C)
We can perfectly fit the line on the following data so mean error volition be zero.
Question Context 27-28:
Suppose you have been given the following scenario for preparation and validation error for Linear Regression.
| Scenario | Learning Rate | Number of iterations | Training Mistake | Validation Error |
| 1 | 0.1 | g | 100 | 110 |
| 2 | 0.ii | 600 | ninety | 105 |
| iii | 0.iii | 400 | 110 | 110 |
| 4 | 0.iv | 300 | 120 | 130 |
| 5 | 0.iv | 250 | 130 | 150 |
27) Which of the following scenario would give you the right hyper parameter?
A) 1
B) 2
C) 3
D) four
Solution: (B)
Option B would be the amend option because it leads to less training as well equally validation mistake.
28) Suppose you got the tuned hyper parameters from the previous question. Now, Imagine you lot want to add a variable in variable space such that this added feature is important. Which of the following affair would yous find in such case?
A) Training Error will decrease and Validation error will increase
B) Preparation Error volition increase and Validation mistake will increase
C) Preparation Mistake will increment and Validation error will decrease
D) Training Error will subtract and Validation error will decrease
Eastward) None of the above
Solution: (D)
If the added feature is of import, the training and validation error would decrease.
Question Context 29-xxx:
Suppose, you got a state of affairs where you detect that your linear regression model is nether fitting the data.
29) In such situation which of the following options would yous consider?
- Add more variables
- Start introducing polynomial degree variables
- Remove some variables
A) 1 and 2
B) 2 and 3
C) 1 and 3
D) i, two and iii
Solution: (A)
In instance of under plumbing equipment, you need to induce more variables in variable space or you tin can add some polynomial degree variables to brand the model more complex to be able to fir the data meliorate.
30) At present situation is aforementioned as written in previous question(under fitting).Which of following regularization algorithm would you prefer?
A) L1
B) L2
C) Any
D) None of these
Solution: (D)
I won't use any regularization methods considering regularization is used in case of overfitting.
End Notes
I tried my best to brand the solutions as comprehensive as possible but if you accept any questions / doubts please driblet in your comments below. I would honey to hear your feedback almost the skilltest. For more such skilltests, check out our electric current hackathons.

Source: https://www.analyticsvidhya.com/blog/2017/07/30-questions-to-test-a-data-scientist-on-linear-regression/
Posted by: gordonquamblus.blogspot.com
0 Response to "Which Of The Following Changes Would Not Be Accounted For Using The Prospective Approach?"
Post a Comment